
一、问题
首先,我们思考这样一个问题:
访问k8s集群中的pod, 客户端需要知道pod地址,需要感知pod的状态。那如何获取各个pod的地址?若某一node上的pod故障,客户端如何感知?
二、k8s service
什么是service
是发现后端pod服务;
是为一组具有相同功能的容器应用提供一个统一的入口地址;
是将请求进行负载分发到后端的各个容器应用上的控制器。
对service的访问来源
访问service的请求来源有两种:k8s集群内部的程序(Pod)和 k8s集群外部的程序。
service类型
采用微服务架构时,作为服务所有者,除了实现业务逻辑以外,还需要考虑如何把服务发布到k8s集群或者集群外部,使这些服务能够被k8s集群内的应用、其他k8s集群的应用以及外部应用使用。因此k8s提供了灵活的服务发布方式,用户可以通过ServiceType来指定如何来发布服务,类型有以下几种:
● ClusterIP:提供一个集群内部的虚拟IP以供Pod访问(service默认类型)。
service 结构如下:
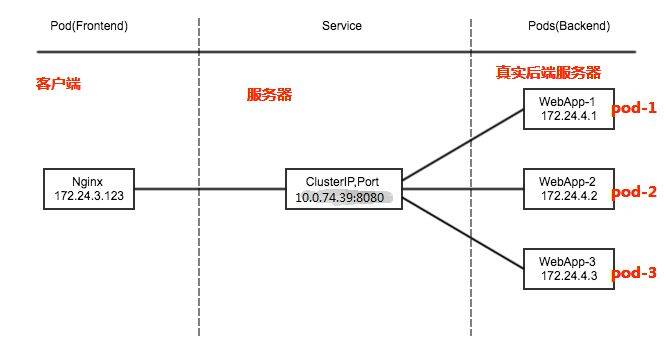
● NodePort:在每个Node上打开一个端口以供外部访问
Kubernetes将会在每个Node上打开一个端口并且每个Node的端口都是一样的,通过:NodePort的方式Kubernetes集群外部的程序可以访问Service。
● LoadBalancer:通过外部的负载均衡器来访问
service selector
service通过selector和pod建立关联。
k8s会根据service关联到pod的podIP信息组合成一个endpoint。
若service定义中没有selector字段,service被创建时,endpoint controller不会自动创建endpoint。
service负载分发策略
service 负载分发策略有两种:
1 | RoundRobin:轮询模式,即轮询将请求转发到后端的各个pod上(默认模式); |
三、服务发现
k8s服务发现方式
虽然Service解决了Pod的服务发现问题,但不提前知道Service的IP,怎么发现service服务呢?
k8s提供了两种方式进行服务发现:
● 环境变量: 当创建一个Pod的时候,kubelet会在该Pod中注入集群内所有Service的相关环境变量。需要注意的是,要想一个Pod中注入某个Service的环境变量,则必须Service要先比该Pod创建。这一点,几乎使得这种方式进行服务发现不可用。
1 | 例如: |
● DNS:可以通过cluster add-on的方式轻松的创建KubeDNS来对集群内的Service进行服务发现————这也是k8s官方强烈推荐的方式。为了让Pod中的容器可以使用kube-dns来解析域名,k8s会修改容器的/etc/resolv.conf配置。
k8s服务发现原理
● endpoint
endpoint是k8s集群中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址。
service配置selector,endpoint controller才会自动创建对应的endpoint对象;否则,不会生成endpoint对象.
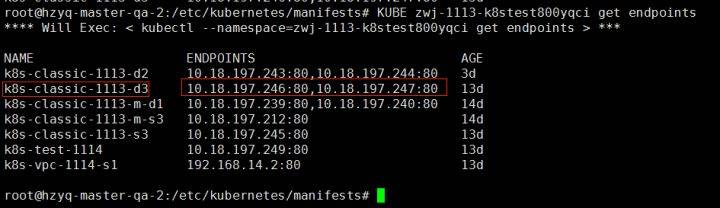
1 | 例如,k8s集群中创建一个名为k8s-classic-1113-d3的service,就会生成一个同名的endpoint对象,如下图所示。其中ENDPOINTS就是service关联的pod的ip地址和端口。 |
● endpoint controller
endpoint controller是k8s集群控制器的其中一个组件,其功能如下:
- 负责生成和维护所有endpoint对象的控制器
- 负责监听service和对应pod的变化
- 监听到service被删除,则删除和该service同名的endpoint对象
- 监听到新的service被创建,则根据新建service信息获取相关pod列表,然后创建对应endpoint对象
- 监听到service被更新,则根据更新后的service信息获取相关pod列表,然后更新对应endpoint对象
- 监听到pod事件,则更新对应的service的endpoint对象,将podIp记录到endpoint中
四、负载均衡
kube-proxy
kube-proxy负责service的实现,即实现了k8s内部从pod到service和外部从node port到service的访问。
kube-proxy采用iptables的方式配置负载均衡,基于iptables的kube-proxy的主要职责包括两大块:一块是侦听service更新事件,并更新service相关的iptables规则,一块是侦听endpoint更新事件,更新endpoint相关的iptables规则(如 KUBE-SVC-链中的规则),然后将包请求转入endpoint对应的Pod。如果某个service尚没有Pod创建,那么针对此service的请求将会被drop掉。
kube-proxy的架构如下: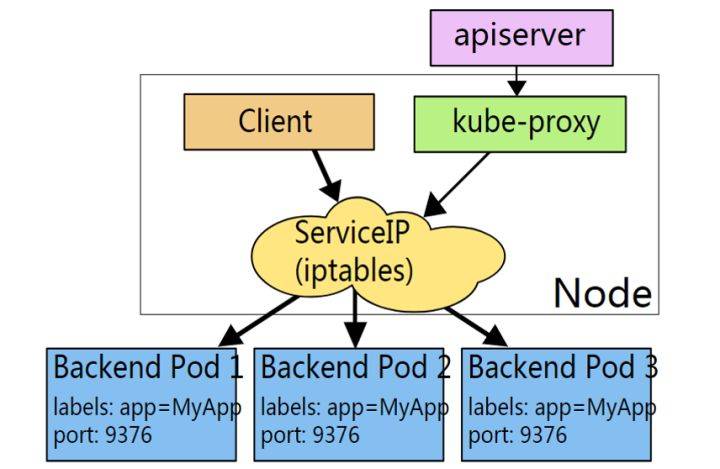
kube-proxy iptables
kube-proxy监听service和endpoint的变化,将需要新增的规则添加到iptables中。
kube-proxy只是作为controller,而不是server,真正服务的是内核的netfilter,体现在用户态则是iptables。
kube-proxy的iptables方式也支持RoundRobin(默认模式)和SessionAffinity负载分发策略。
kubernetes只操作了filter和nat表。
Filter:在该表中,一个基本原则是只过滤数据包而不修改他们。filter table的优势是小而快,可以hook到input,output和forward。这意味着针对任何给定的数据包,只有可能有一个地方可以过滤它。
NAT:此表的主要作用是在PREROUTING和POSTROUNTING的钩子中,修改目标地址和原地址。与filter表稍有不同的是,该表中只有新连接的第一个包会被修改,修改的结果会自动apply到同一连接的后续包中。
kube-proxy对iptables的链进行了扩充,自定义了KUBE-SERVICES,KUBE-NODEPORTS,KUBE-POSTROUTING,KUBE-MARK-MASQ和KUBE-MARK-DROP五个链,并主要通过为KUBE-SERVICES chain增加rule来配制traffic routing 规则。我们可以看下自定义的这几个链的作用:
1 | KUBE-MARK-DROP - [0:0] /*对于未能匹配到跳转规则的traffic set mark 0x8000,有此标记的数据包会在filter表drop掉*/ |
同时,kube-proxy也为默认的prerouting、output和postrouting chain增加规则,使得数据包可以跳转至k8s自定义的chain,规则如下:
1 | -A PREROUTING -m comment --comment "kubernetes service portals" -j KUBE-SERVICES |
如果service类型为nodePort,(从LB转发至node的数据包均属此类)那么将KUBE-NODEPORTS链中每个目的地址是NODE节点端口的数据包导入这个“KUBE-SVC-”链:
1 | -A KUBE-SERVICES -m comment --comment "kubernetes service nodeports; NOTE: this must be the last rule in this chain" -m addrtype --dst-type LOCAL -j KUBE-NODEPORTS |
Iptables chain支持嵌套并因为依据不同的匹配条件可支持多种分支,比较难用标准的流程图来体现调用关系,建单抽象为下图: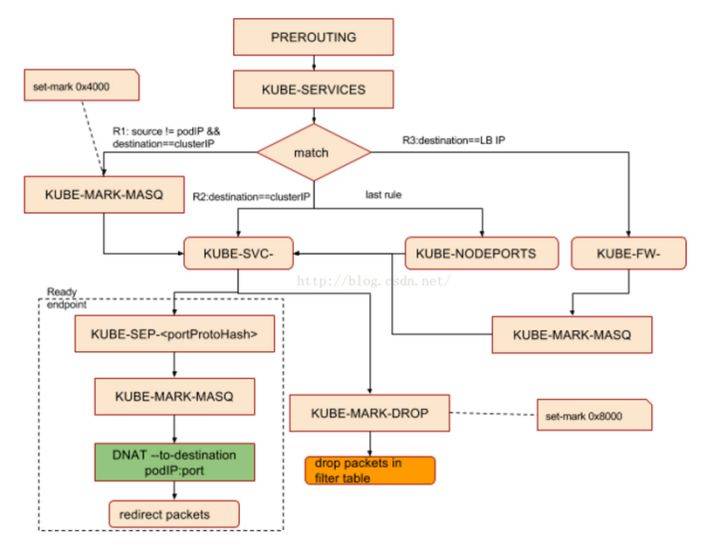
举个例子,在k8s集群中创建了一个名为my-service的服务,其中:
service vip:10.11.97.177
对应的后端两副本pod ip:10.244.1.10、10.244.2.10
容器端口为:80
服务端口为:80
则kube-proxy为该service生成的iptables规则主要有以下几条:
1 | -A KUBE-SERVICES -d 10.11.97.177/32 -p tcp -m comment --comment "default/my-service: cluster IP" -m tcp --dport 80 -j KUBE-SVC-BEPXDJBUHFCSYIC3 |
kube-proxy通过循环的方式创建后端endpoint的转发,概率是通过probability后的1.0/float64(n-i)计算出来的,譬如有两个的场景,那么将会是一个0.5和1也就是第一个是50%概率第二个是100%概率,如果是三个的话类似,33%、50%、100%。
kube-proxy iptables的性能缺陷
k8s集群创建大规模服务时,会产生很多iptables规则,非增量式更新会引入一定的时延。iptables规则成倍增长,也会导致路由延迟带来访问延迟。大规模场景下,k8s 控制器和负载均衡都面临这挑战。例如,若集群中有N个节点,每个节点每秒有M个pod被创建,则控制器每秒需要创建N_M个endpoints,需要增加的iptables则是N_M的数倍。以下是k8s不同规模下访问service的时延: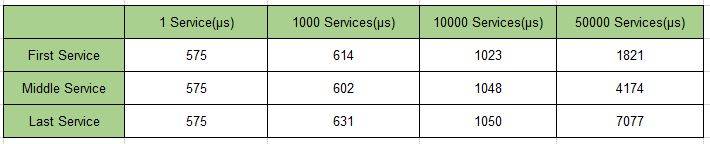
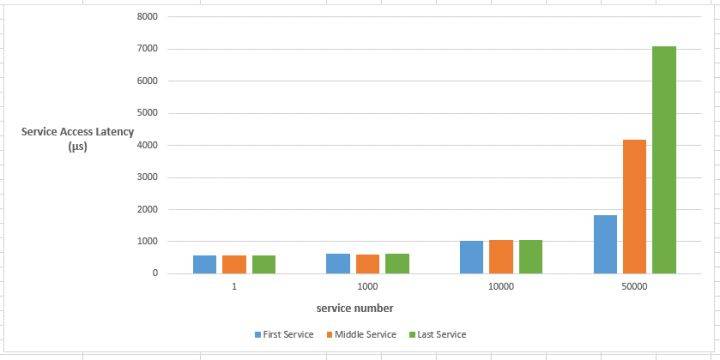
从上图中可以看出,当集群中服务数量增长时,因为 IPTables天生不是被设计用来作为 LB 来使用的,IPTables 规则则会成倍增长,这样带来的路由延迟会导致的服务访问延迟增加,直到无法忍受。
目前有以下几种解决方案,但各有不足:
● 将endpoint对象拆分成多个对像
1 | 优点:减小了单个endpoint大小 |
● 使用集中式负载均衡器
1 | 优点:减少了跟apiserver的连接和请求数 |
● 定期任务,批量创建/更新endpoint
1 | 优点:减少了每秒的处理数 |
五、K8s 1.8 新特性——ipvs
ipvs与iptables的性能差异
随着服务的数量增长,IPTables 规则则会成倍增长,这样带来的问题是路由延迟带来的服务访问延迟,同时添加或删除一条规则也有较大延迟。不同规模下,kube-proxy添加一条规则所需时间如下所示: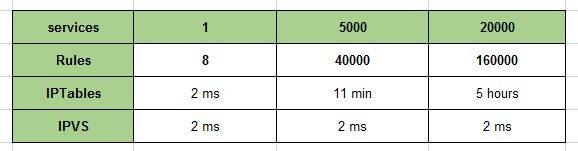
可以看出当集群中服务数量达到5千个时,路由延迟成倍增加。添加 IPTables 规则的延迟,有多种产生的原因,如:
添加规则不是增量的,而是先把当前所有规则都拷贝出来,再做修改然后再把修改后的规则保存回去,这样一个过程的结果就是 IPTables 在更新一条规则时会把 IPTables 锁住,这样的后果在服务数量达到一定量级的时候,性能基本不可接受:在有5千个服务(4万条规则)时,添加一条规则耗时11分钟;在右2万个服务(16万条规则)时,添加一条规则需要5个小时。
这样的延迟时间,对生产环境是不可以的,那该性能问题有哪些解决方案呢?从根本上解决的话,可以使用 “IP Virtual Server”(IPVS )来替换当前 kube-proxy 中的 IPTables 实现,这样能带来显著的性能提升以及更智能的负载均衡功能如支持权重、支持重试等等。
那什么是 “IP Virtual Server”(IPVS ) 呢?
ipvs 简介
k8s 1.8 版本中,社区 SIG Network 增强了 NetworkPolicy API,以支持 Pod 出口流量策略,以及允许策略规则匹配源或目标 CIDR 的匹配条件。这两个增强特性都被设计为 beta 版本。 SIG Network 还专注于改进 kube-proxy,除了当前的 iptables 和 userspace 模式,kube-proxy 还引入了一个 alpha 版本的 IPVS 模式。
作为 Linux Virtual Server(LVS) 项目的一部分,IPVS 是建立于 Netfilter之上的高效四层负载均衡器,支持 TCP 和 UDP 协议,支持3种负载均衡模式:NAT、直接路由(通过 MAC 重写实现二层路由)和IP 隧道。ipvs(IP Virtual Server)安装在LVS(Linux Virtual Server)集群作为负载均衡主节点上,通过虚拟出一个IP地址和端口对外提供服务。客户端通过访问虚拟IP+端口访问该虚拟服务,之后访问请求由负载均衡器调度到后端真实服务器上。
ipvs相当于工作在netfilter中的input链。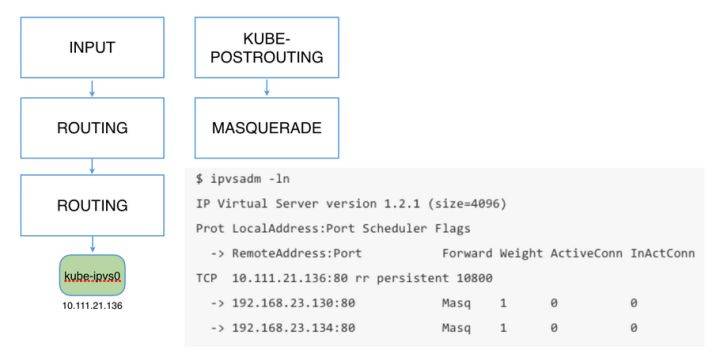
配置方法:IPVS 负载均衡模式在 kube-proxy 处于测试阶段还未正式发布,完全兼容当前 Kubernetes 的行为,通过修改 kube-proxy 启动参数,在 mode=userspace 和 mode=iptables 的基础上,增加 mode=IPVS 即可启用该功能。
ipvs转发模式
● DR模式(Direct Routing)
特点:
<1> 数据包在LB转发过程中,源/目的IP和端口都不会变化。LB只修改数据包的MAC地址为RS的MAC地址
<2> RS须在环回网卡上绑定LB的虚拟机服务IP
<3> RS处理完请求后,响应包直接回给客户端,不再经过LB
缺点:
<1> LB和RS必须位于同一子网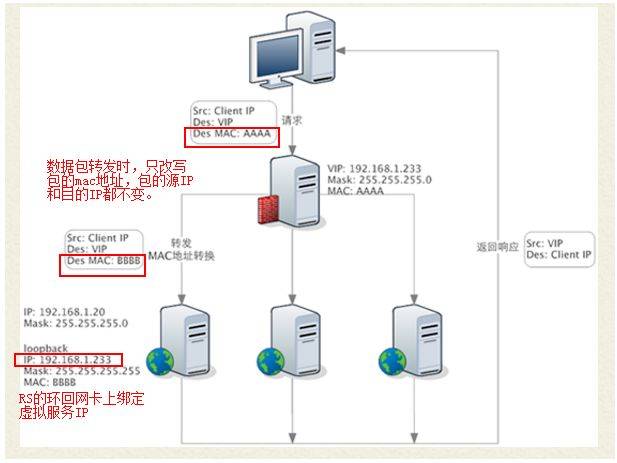
● NAT模式(Network Address Translation)
特点:
<1> LB会修改数据包地址:对于请求包,进行DNAT;对于响应包,进行SNAT
<2> 需要将RS的默认网关地址配置为LB的虚拟IP地址
缺点:
<1> LB和RS必须位于同一子网,且客户端和LB不能位于同一子网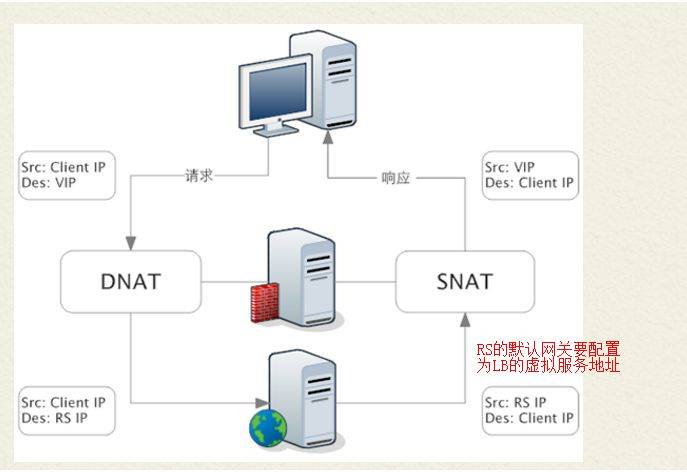
● FULLNAT模式
特点:
<1> LB会对请求包和响应包都做SNAT+DNAT
<2> LB和RS对于组网结构没有要求
<3> LB和RS必须位于同一子网,且客户端和LB不能位于同一子网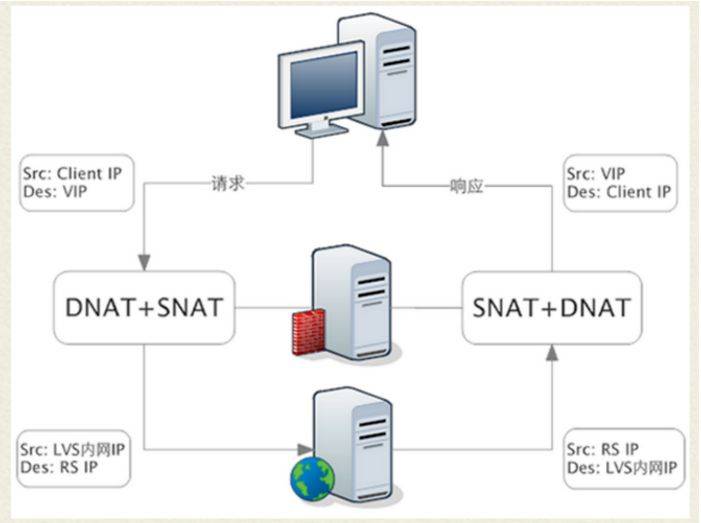
● 三种转发模式性能从高到低:DR > NAT >FULLNAT
ipvs 负载均衡器常用调度算法
● 轮询(Round Robin)
LB认为集群内每台RS都是相同的,会轮流进行调度分发。从数据统计上看,RR模式是调度最均衡的。
● 加权轮询(Weighted Round Robin)
LB会根据RS上配置的权重,将消息按权重比分发到不同的RS上。可以给性能更好的RS节点配置更高的权重,提升集群整体的性能。
● 最少连接调度
LB会根据和集群内每台RS的连接数统计情况,将消息调度到连接数最少的RS节点上。在长连接业务场景下,LC算法对于系统整体负载均衡的情况较好;但是在短连接业务场景下,由于连接会迅速释放,可能会导致消息每次都调度到同一个RS节点,造成严重的负载不均衡。
● 加权最少连接调度
最小连接数算法的加权版。
● 原地址哈希,锁定请求的用户
根据请求的源IP,作为散列键(Hash Key)从静态分配的散列表中找出对应的服务器。若该服务器是可用的且未超载,将请求发送到该服务器。
原文出处
作者:陈Sir的知识库
---本文结束感谢您的阅读。微信扫描二维码,关注我的公众号---

本文链接: https://www.yp14.cn/2020/02/09/kubernetes-service-介绍/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!

