
- 作者:二二向箔
- 链接:https://www.jianshu.com/p/ef9879dfb9ef
概述
Prometheus提供了本地存储,即tsdb时序数据库,本地存储给Prometheus带来了简单高效的使用体验,prometheus2.0以后压缩数据能力也得到了很大的提升。可以在单节点的情况下满足大部分用户的监控需求。
但本地存储也限制了Prometheus的可扩展性,带来了数据持久化等一系列的问题。为了解决单节点存储的限制,prometheus没有自己实现集群存储,而是提供了远程读写的接口,让用户自己选择合适的时序数据库来实现prometheus的扩展性。
Prometheus 1.x版本的TSDB(V2存储引擎)基于LevelDB,并且使用了和Facebook Gorilla一样的压缩算法,能够将16个字节的数据点压缩到平均1.37个字节。
Prometheus 2.x版本引入了全新的V3存储引擎,提供了更高的写入和查询性能
以下所有内容均基于prometheus2.7版本
本地存储
存储原理
Prometheus按2小时一个block进行存储,每个block由一个目录组成,该目录里包含:一个或者多个chunk文件(保存timeseries数据)、一个metadata文件、一个index文件(通过metric name和labels查找timeseries数据在chunk文件的位置)。
最新写入的数据保存在内存block中,达到2小时后写入磁盘。为了防止程序崩溃导致数据丢失,实现了WAL(write-ahead-log)机制,启动时会以写入日志(WAL)的方式来实现重播,从而恢复数据。
删除数据时,删除条目会记录在独立的tombstone文件中,而不是立即从chunk文件删除。
通过时间窗口的形式保存所有的样本数据,可以明显提高Prometheus的查询效率,当查询一段时间范围内的所有样本数据时,只需要简单的从落在该范围内的块中查询数据即可。
这些2小时的block会在后台压缩成更大的block,数据压缩合并成更高level的block文件后删除低level的block文件。这个和leveldb、rocksdb等LSM树的思路一致。
这些设计和Gorilla的设计高度相似,所以Prometheus几乎就是等于一个缓存TSDB。它本地存储的特点决定了它不能用于long-term数据存储,只能用于短期窗口的timeseries数据保存和查询,并且不具有高可用性(宕机会导致历史数据无法读取)。
内存中的block数据未写入磁盘时,block目录下面主要保存wal文件:
1 | ./data/01BKGV7JBM69T2G1BGBGM6KB12 |
持久化的block目录下wal文件被删除,timeseries数据保存在chunk文件里。index用于索引timeseries在wal文件里的位置。
1 | ./data/01BKGV7JC0RY8A6MACW02A2PJD |
存储配置
对于本地存储,prometheus提供了一些配置项,主要包括:
- --storage.tsdb.path: 存储数据的目录,默认为data/,如果要挂外部存储,可以指定该目录
- --storage.tsdb.retention.time: 数据过期清理时间,默认保存15天
- --storage.tsdb.retention.size: 实验性质,声明数据块的最大值,不包括wal文件,如512MB
- --storage.tsdb.retention: 已被废弃,改为使用storage.tsdb.retention.time
Prometheus将所有当前使用的块保留在内存中。此外,它将最新使用的块保留在内存中,最大内存可以通过storage.local.memory-chunks标志配置。
监测当前使用的内存量:
- prometheus_local_storage_memory_chunks
- process_resident_memory_bytes
监测当前使用的存储指标:
- prometheus_local_storage_memory_series: 时间序列持有的内存当前块数量
- prometheus_local_storage_memory_chunks: 在内存中持久块的当前数量
- prometheus_local_storage_chunks_to_persist: 当前仍然需要持久化到磁盘的的内存块数量
- prometheus_local_storage_persistence_urgency_score: 紧急程度分数
prometheus 2.0的存储升级
prometheus 2.0于2017-11-08发布,主要是存储引擎进行了优化。
性能的整体提高:
- 与 Prometheus 1.8 相比,CPU使用率降低了 20% - 40%
- 与 Prometheus 1.8 相比,磁盘空间使用率降低了 33% - 50%
- 没有太多查询,平均负载的磁盘 I/O<1%
在Kubernetes集群这样的动态环境中,prometheus的数据平面通常看起来是这种样式
- 垂直维度表示所有存储的序列
- 水平维度表示样本传播的时间
如:
1 | requests_total{path="/status", method="GET", instance="10.0.0.1:80"} |

Prometheus定期为所有系列收集新数据点,这意味着它必须在时间轴的右端执行垂直写入。但是,在查询时,我们可能希望访问平面上任意区域的矩形(各种label条件)
因此为了能够在大量数据中有效地查找查询序列,我们需要一个索引。
在Prometheus 1.x存储层可以很好地处理垂直写入模式,但是随着规模增大,索引或出现一些问题,因此在2.0版本中重新设计了存储引擎和索引,主要改造是:
样本压缩
现有存储层的样本压缩功能在Prometheus的早期版本中发挥了重要作用。单个原始数据点占用16个字节的存储空间。但当普罗米修斯每秒收集数十万个数据点时,可以快速填满硬盘。
但,同一系列中的样本往往非常相似,我们可以利用这一类样品(同样label)进行有效的压缩。批量压缩一系列的许多样本的块,在内存中,将每个数据点压缩到平均1.37字节的存储。
这种压缩方案运行良好,也保留在新版本2存储层的设计中。具体压缩算法可以参考:Facebook的“Gorilla”论文中
时间分片
我们将新的存储层划分为块(block),每个块在一段时间内保存所有序列。每个块充当独立数据库。
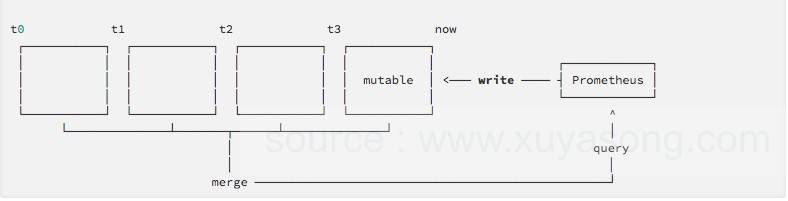
这样每次查询,仅检查所请求的时间范围内的块子集,查询执行时间自然会减少。
这种布局也使删除旧数据变得非常容易(这在1.x的存储设计中是一个很耗时的操作)。但在2.x中,一旦块的时间范围完全落后于配置的保留边界,它就可以完全丢弃。

索引
一般prometheus的查询是把metric+label做关键字的,而且是很宽泛,完全用户自定义的字符,因此没办法使用常规的sql数据库,prometheus的存储层使用了全文检索中的倒排索引概念,将每个时间序列视为一个小文档。而metric和label对应的是文档中的单词。
例如,requests_total{path=”/status”, method=”GET”, instance=”10.0.0.1:80”}是包含以下单词的文档:
- name=”requests_total”
- path=”/status”
- method=”GET”
- instance=”10.0.0.1:80”
基准测试
cpu、内存、查询效率都比1.x版本得到了大幅度的提升
具体测试结果参考:https://dzone.com/articles/prometheus-2-times-series-storage-performance-anal
故障恢复
如果您怀疑数据库中的损坏引起的问题,则可以通过使用storage.local.dirtyflag配置,来启动服务器来强制执行崩溃恢复。
如果没有帮助,或者如果您只想删除现有的数据库,可以通过删除存储目录的内容轻松地启动:
- 1.停止服务:stop prometheus.
- 2.删除数据目录:rm -r /storage path/*
- 3.启动服务:start prometheus
远程存储
Prometheus默认是自己带有存储的,保存的时间为15天。但本地存储也意味着Prometheus无法持久化数据,无法存储大量历史数据,同时也无法灵活扩展。
为了保证Prometheus的简单性,Prometheus并没有从自身集群的维度来解决这些问题,而是定义了两种接口,remote_write/remote_read,将数据抛出去,你自己处理。
Prometheus的remote_storage 其实是一个adapter,至于在adapter的另一端是什么类型的时序数据库它根本不关心,如果你愿意,你也可以编写自己的adpater。
如:存储的方式为:Prometheus —-发送数据—- > remote_storage_adapter —- 存储数据 —-> influxdb。
prometheus通过下面两种方式来实现与其他的远端存储系统对接:
- Prometheus 按照标准的格式将metrics写到远端存储
- Prometheus 按照标准格式从远端的url来读取metrics

远程读
在远程读的流程当中,当用户发起查询请求后,Promthues将向remote_read中配置的URL发起查询请求(matchers,ranges),Adaptor根据请求条件从第三方存储服务中获取响应的数据。同时将数据转换为Promthues的原始样本数据返回给Prometheus Server。
当获取到样本数据后,Promthues在本地使用PromQL对样本数据进行二次处理。
远程写
用户可以在Promtheus配置文件中指定Remote Write(远程写)的URL地址,一旦设置了该配置项,Prometheus将样本数据通过HTTP的形式发送给适配器(Adaptor)。而用户则可以在适配器中对接外部任意的服务。外部服务可以是真正的存储系统,公有云的存储服务,也可以是消息队列等任意形式。
配置
配置非常简单,只需要将对应的地址配置下就行
1 | remote_write: |
社区支持
现在社区已经实现了以下的远程存储方案
- AppOptics: write
- Chronix: write
- Cortex: read and write
- CrateDB: read and write
- Elasticsearch: write
- Gnocchi: write
- Graphite: write
- InfluxDB: read and write
- OpenTSDB: write
- PostgreSQL/TimescaleDB: read and write
- SignalFx: write
可以使用读写完整的InfluxDB,我们使用了多prometheus server同时远程读+写,验证了速度还是可以的。并且InfluxDB生态完整,自带了很多管理工具。
容量规划
在一般情况下,Prometheus中存储的每一个样本大概占用1-2字节大小。如果需要对Prometheus Server的本地磁盘空间做容量规划时,可以通过以下公式计算:
1 | 磁盘大小 = 保留时间 * 每秒获取样本数 * 样本大小 |
保留时间(retention_time_seconds)和样本大小(bytes_per_sample)不变的情况下,如果想减少本地磁盘的容量需求,只能通过减少每秒获取样本数(ingested_samples_per_second)的方式。
因此有两种手段,一是减少时间序列的数量,二是增加采集样本的时间间隔。
考虑到Prometheus会对时间序列进行压缩,因此减少时间序列的数量效果更明显。
其他
远程读写解决了Promtheus的数据持久化问题。使其可以进行弹性扩展。另外还支持联邦集群模式,用于解决横向扩展、网络分区的问题(如地域A+B+C的监控数据,统一汇总到D),联邦集群的配置将在后面的Promthues高可用文章中详细说明。
参考资料
- https://prometheus.io/docs/prometheus/latest/storage/
- https://coreos.com/blog/prometheus-2.0-storage-layer-optimization?utm_source=blog&utm_medium=referral
- https://dzone.com/articles/prometheus-2-times-series-storage-performance-anal
- https://www.linuxidc.com/Linux/2018-04/152057.htm
- http://ylzheng.com/2018/03/06/promethus-local-storage/
- https://www.cnblogs.com/vovlie/p/7709312.html
- https://files-cdn.cnblogs.com/files/vovlie/copyofprometheusstorage1-160127133731.pdf
- https://www.bookstack.cn/read/prometheus-manual/operating-storage.md?wd=%E5%A4%A7%E4%BA%8E。
---本文结束感谢您的阅读。微信扫描二维码,关注我的公众号---

本文链接: https://www.yp14.cn/2020/03/02/容器监控实践—Prometheus存储机制/
版权声明: 本作品采用 知识共享署名-非商业性使用-相同方式共享 4.0 国际许可协议 进行许可。转载请注明出处!

