Kui 简介
Kui 为构建云原生应用程序提供了新的开发经验。Kui使您能够操作复杂的 JSON 和 YAML 数据模型,集成不同的工具,并提供对操作数据的聚合视图快速访问。
演示
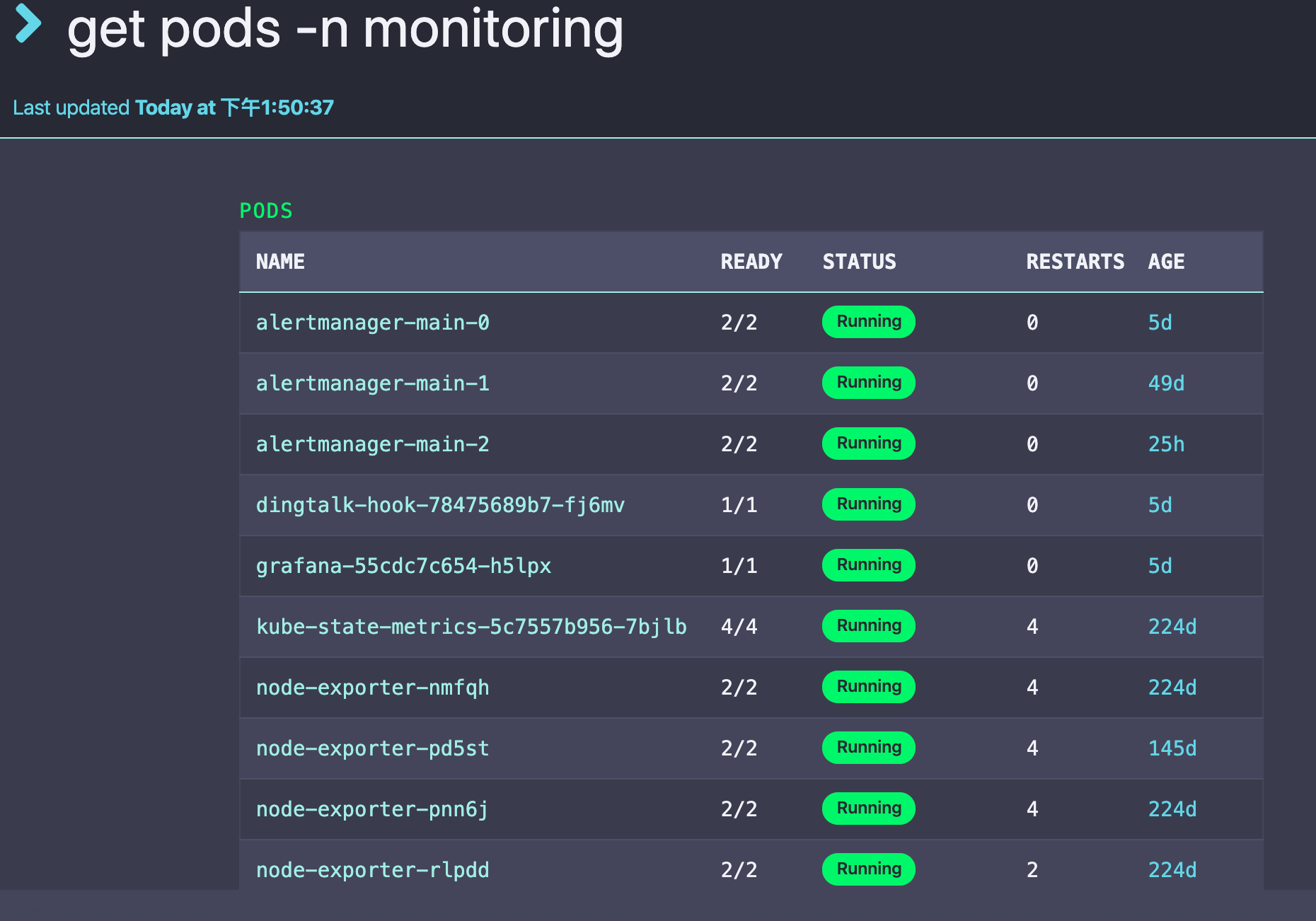
1 | # 查看 monitoring 命名空间中 pods |
1 | # 查看 deployment 概要 |

闪射理想之光吧心灵之星!把光流注入未来的暮霭之中。
如果你使用过
kubeadm部署过Kubernetes的环境,master主机节点上就一定会在相应的目录创建了一大批证书文件, 本篇文章就来说说kubeadm到底为我们生成了哪些证书。
在Kubernetes的部署中, 创建证书, 配置证书是一道绕不过去坎儿, 好在有kubeadm这样的自动化工具, 帮我们去生成, 配置这些证书. 对于只是想体验Kubernetes或只是想测试的亲来说, 这已经够了, 但是作为Kubernetes的集群维护者来说, kubeadm更像是一个黑盒, 本篇文章就来说说黑盒中关于证书的事儿~
使用kubeadm创建完Kubernetes集群后, 默认会在 /etc/kubernetes/pki 目录下存放集群中需要用到的证书文件, 整体结构如下图所示:
集群中有台node服务器因为资源达到上限出现假死现状,重启后发现calico node 无法启动成功,提示如下信息:
1 | :Readiness probe failed: caliconode is not ready: BIRD is not ready: BGP not established with 172.18.0.1 |
使用 calicoctl node status 命令查看node状态信息提示如下:
1 | Calico process is running. |
当 Kubernetes 中 Node 节点出现状态异常的情况下,节点上的 Pod 会被重新调度到其他节点上去,但是有的时候我们会发现节点 Down 掉以后,Pod 并不会立即触发重新调度,这实际上就是和 Kubelet 的状态更新机制密切相关的,Kubernetes 提供了一些参数配置来触发重新调度到嗯时间,下面我们来分析下 Kubelet 状态更新的基本流程。
--node-status-update-frequency 指定上报频率,默认是 10s 上报一次。--node-monitor-period 时间去检查 kubelet 的状态,默认是 5s。notready 状态,这段时长通过 --node-monitor-grace-period 参数配置,默认 40s。unhealthy 状态,这段时长通过 --node-startup-grace-period 参数配置,默认 1m0s。--pod-eviction-timeout 参数配置,默认 5m0skube-controller-manager 和 kubelet 是异步工作的,这意味着延迟可能包括任何的网络延迟、apiserver 的延迟、etcd 延迟,一个节点上的负载引起的延迟等等。因此,如果
--node-status-update-frequency设置为5s,那么实际上 etcd 中的数据变化会需要 6-7s,甚至更长时间。Kubelet在更新状态失败时,会进行nodeStatusUpdateRetry次重试,默认为5 次。
Kubelet 会在函数 tryUpdateNodeStatus 中尝试进行状态更新。Kubelet 使用了 Golang 中的 http.Client() 方法,但是没有指定超时时间,因此,如果 API Server 过载时,当建立 TCP 连接时可能会出现一些故障。
因此,在 nodeStatusUpdateRetry * --node-status-update-frequency 时间后才会更新一次节点状态。
同时,Kubernetes 的 controller manager 将尝试每 --node-monitor-period 时间周期内检查nodeStatusUpdateRetry 次。在 --node-monitor-grace-period 之后,会认为节点 unhealthy,然后会在--pod-eviction-timeout 后删除 Pod。
kube proxy 有一个 watcher API,一旦 Pod 被驱逐了,kube proxy 将会通知更新节点的 iptables 规则,将 Pod 从 Service 的 Endpoints 中移除,这样就不会访问到来自故障节点的 Pod 了。
对于 tcpdump 的使用,大部分管理员会分成两类。有一类管理员,他们熟知 tcpdump 和其中的所有标记;另一类管理员,他们仅了解基本的使用方法,剩下事情都要借助参考手册才能完成。出现这种情况的原因在于, tcpdump 是一个相当高级的命令,使用的时候需要对网络的工作机制有相当深入的了解。
在今天的文章中,我想提供一个快速但相当实用的 tcpdump 参考。我会谈到基本的和一些高级的使用方法。我敢肯定我会忽略一些相当酷的命令,欢迎你补充在评论部分。
在我们深入了解以前,最重要的是了解 tcpdump 是用来做什么的。 tcpdump 命令用来保存和记录网络流量。你可以用它来观察网络上发生了什么,并可用来解决各种各样的问题,包括和网络通信无关的问题。除了网络问题,我经常用 tcpdump 解决应用程序的问题。如果你发现两个应用程序之间无法很好工作,可以用 tcpdump 观察出了什么问题。 tcpdump 可以用来抓取和读取数据包,特别是当通信没有被加密的时候。
示例:
1 | location = / { |
在 Kubernetes 开源生态中,资源监控有 metrics-server、Prometheus等,但这些监控并不能实时推送 Kubernetes 事件,监控准确性也不足。当 kubernetes 集群中发生 Pod因为 OOM 、拉取不到镜像、健康检查不通过等错误导致重启,集群管理员其实是不知道的,因为 Kubernetes 有自我修复机制,Pod宕掉,可以重新启动一个。这样让集群管理员很难立即发现服务问题。
Kubernetes中,事件分为两种:
Warning事件:表示产生这个事件的状态转换是在非预期的状态之间产生的Normal事件:表示期望到达的状态,和目前达到的状态是一致的ELK 是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch、Logstash 和 Kibana。
Elasticsearch 是一个分布式的开源搜索和分析引擎,适用于所有类型的数据,包括文本、数字、地理空间、结构化和非结构化数据。Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。Elasticsearch 在速度和可扩展性方面都表现出色,而且还能够索引多种类型的内容,这意味着其可用于多种用例:
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true